网络IO模型,从同步阻塞到epoll
copyright copyleft copywhatever
June 03, 2016
chng
为什么写这篇
近期一些老师同学与我讨论TCP/IP协议栈中的socket通信的模型,讨论再三,我觉得这样一个重要的基础概念,有必要通过文字的形式记录下来,通过这样的方式做一个思维的梳理。对于《Unix网络编程》 (UNP) 中IO模型一章较熟悉的同学,请直接Ctrl+W吧。
基本知识
-
典型的服务器/客户端(C/S)模型中,服务端打开一个监听端口(例如FTP的22),并绑定(bind)到自己的地址上开始监听(accept),客户端以此为目的端口发起连接(connect),于是开始了TCP三次握手。在服务端的Linux系统会通过accept队列和syn队列来处理客户端的连接请求,这一阶段的具体过程可见陶辉老师的《高性能网络编程》一文。并且显然,一个用于数据通信(或者说进程间通信)的socket的几种行为包括connect,write,read。close四种。
-
进程和线程之间的区别。进程是资源分配的基本单元,线程是CPU调度的基本单元。窃以为大家听这句话都听出老茧了,但还是想说下,因为和下文有关。socket也是一种资源,是要占用一个文件描述符(File Description, fd)的。 进一步地,socket端口也仅仅是一种普通资源,一个进程可以拥有一个或多个socket,因此不要局限性地认为端口和进程是一一对应的关系。
-
IO操作是数据在进程和载体之间传输的必要操作,也一种代价很高的操作,其中网络IO最慢,磁盘IO次之。
同步阻塞IO
同步阻塞式的IO模型是最简单的:
- 服务端监听并阻塞在accpet函数;
- 客户端发起连接;
- 服务端跳出accept函数,为客户端分配一个socket与客户端之间开始读写操作。
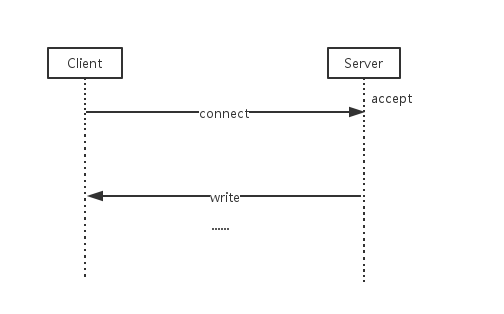
这个模型的缺陷显而易见:当服务端为一个客户端提供服务时,不接受其他客户端的连接请求,毫无并发性。
多线程IO模型
为了解决无并发的问题,可以用多线程的方式使得服务端在服务客户时,还能接受其他客户端的连接:父线程负责监听,以及发起子线程来为客户端提供服务。这也是一种简单的基本模型。
- 服务端监听并阻塞在accept函数;
- 客户端发起连接;
- 服务端跳出accept,通过fork或者pthread_create创建子线程,获取到socket的fd,与客户端交换数据;
- 子线程服务完毕,关闭端口。
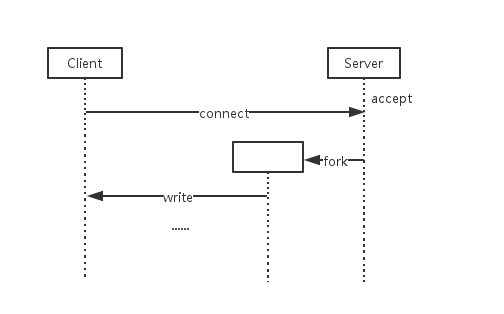
这个模型的缺陷也显而易见的:
- 从代价角度看,不管是fork出进程,还是pthread出线程,都是要代价的,一方面是资源分配的代价,一方面是线程调度的代价,一方面还可能有避免线程安全问题带来的代价,比如锁竞争的代价。而且,如果大量的线程都阻塞在某种重量级的IO操作上(读写大量数据),就会持续占用大量资源。
- 从复用的问题:许多的客户端实际上用的是同样的服务,而服务端却针对不同的用户,开了许多运行相同代码的线程,请了许多工人却都在做一模一样的事,看起来并不优雅。
IO复用模型
为了解决多线程代价太大等问题,考虑能否用单个线程服务多个客户端呢?这就需要提供一种方法,使得这个线程可以轻松高效地管理多个端口,这些端口与多个客户端保持着连接。
生产者-消费者
要使用单个进程给多个客户端提供服务,排队是一种显而易见的方法:对于来自不同客户端的请求和数据包,都先放到一个队列里;而在队列另一头,一个线程用轮询的方式来处理这些请求和数据包,该怎么做就怎么做。
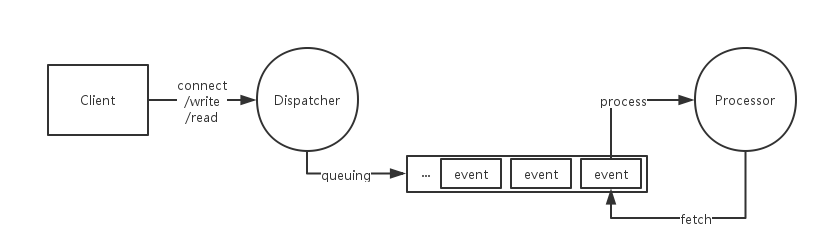
实际上,如果不考虑公平性,我们不需要局限在队列的数据结构中,任何何时的容器都是可以的。简单来说,这个生产者-消费者模型,就是生产者负责把要处理的请求放到一个池子里,消费者从这个池子里拿出请求并处理,这个池子可以是合适的任何一种容器。
反应堆模式
在不引入多个线程异步处理客户端请求的做法的前提下,进行同步事件的分发,这也就是反应堆模式的场合。分发者只负责接收请求,然后分发给不同的处理者去处理。
Linux的支持
Linux的内核对这种单线程管理多端口的IO模型提供了一些支持:
- select模型
- poll模型
- epoll模型
在select模型中,容纳着不同端口的不同请求的这个容器,是两个位图,write位图和read位图。其中1表示这个端口有write或read事件要处理。Linux海提供了系统调用来使得应用程序可以获取到这些位图。应用程序通过系统调用获取到哪些socket需要write,哪些需要read之后,就开始自己的逻辑。然而,select模型一方面受限于位图大小的限制,能“同时”处理的端口数并不多,比如同时管理1024个端口是系统的上限,那么并发量最多为1024。
而poll模型解决的问题,是增大了端口数的这一上限。
select和poll存在一个问题,当应用程序通过系统调用得到了一个端口号的列表,它还需要自己顺序地遍历这个列表,来检查哪些端口有读写事件要处理。一方面是性能问题,不断地顺序遍历一个很大的列表是一个不优雅的事情;一方面是空轮询的问题,如果分派不均,或者系统维护的所有TCP连接的活跃程度很低,即有读写事件的端口数很少,导致列表非常稀疏,进一步导致select和poll做了很多无效的轮训。
而epoll模型解决的就是以上问题。此时,这个池子不再是一个位图或列表,而是一颗平衡二叉树(比如红黑树),通过端口号可以很快查到与某个端口号相关的事件。换了一个池子的实例后,应用程序可以快速地得到有效地端口号集合。
边缘触发(Edge Triggered, ET)和水平触发(Level Triggered, LT)
epoll有两种工作模式,边缘触发ET和水平触发LT。二者的区别在于,LT模式下只要一个端口处于可读或可写的状态,应用程序通过系统调用(epoll_wait函数)就会获得这个端口的读写事件。而ET模式下,只有某个socket从未就绪变为可读或可写的状态时,epoll_wait才会返回该事件。
举个例子,如果客户端像服务端写入2K数据,但每次写入1K。
- 在LT模式下,服务端第一次轮询后处理了前1K数据的读取,在第二次轮询后处理接下来的1K数据。
- 在ET模式下,服务端第一次轮询后处理了前1K数据的读取,在第二次轮询后就不能再感知到这个socket的读取事件了。
基于IO复用模型的应用框架
进一步地,服务端对于这些来自客户端的请求,要做的无非是有限的几种操作:
- 服务端首先阻塞在select操作上,等待任何端口的IO事件;
- 客户端accept,服务端就与它建立连接,并维护与之连接的端口;
- 客户端write,服务端就发起一个read操作,然后也许还要发起write操作;
- 客户端close,服务端也close。
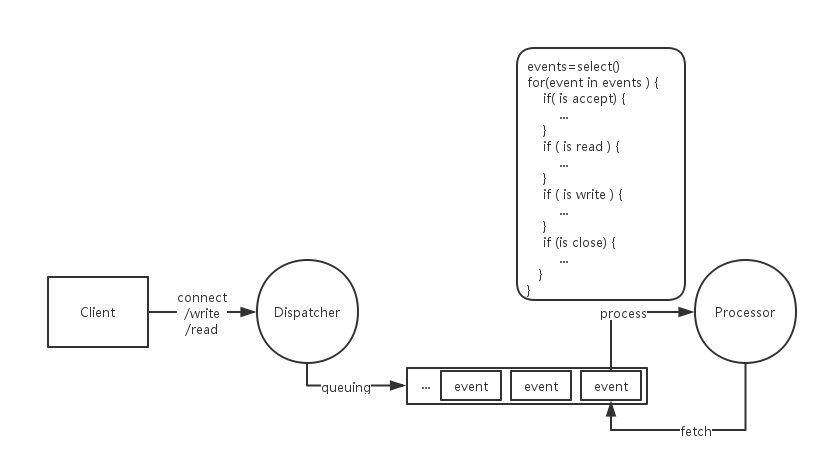
可以将这些共性的、业务无关的代码作为一个框架的一部分封装起来,成为应用的共性部分。常见的IO复用模型的框架有:C家族的libev,Java家族的MINA等等。